Zyphra's TSP: A Smarter Way to Parallelize Large Language Models
Zyphra's TSP combines TP and SP into one axis, reducing memory and boosting throughput up to 2.6x on AMD MI300X GPUs.
The Memory Challenge in Scaling Transformers
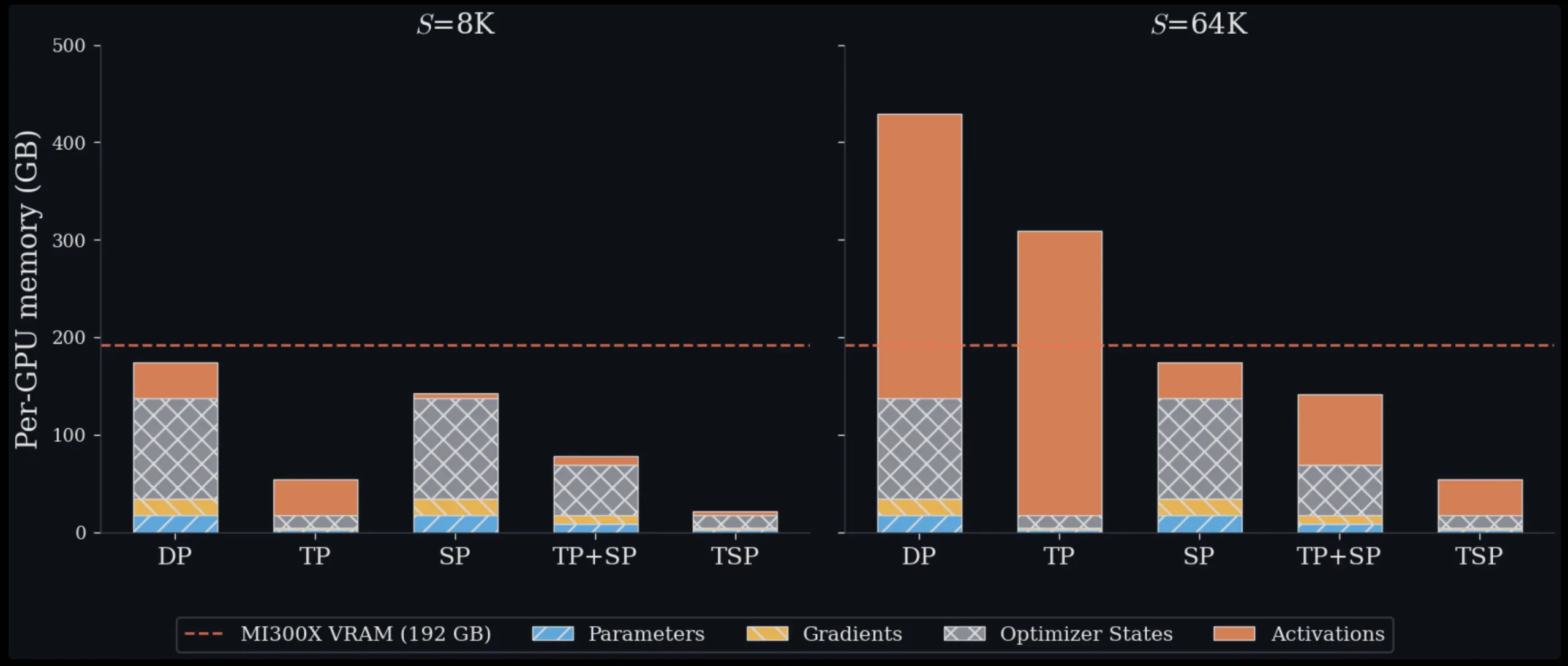
Training and deploying large transformer models at scale is fundamentally a memory management problem. Every GPU in a cluster has a fixed amount of VRAM, and as model sizes and context lengths grow, engineers constantly have to make trade-offs about how to distribute work across hardware. Zyphra has introduced a new technique called Tensor and Sequence Parallelism (TSP) that rethinks these trade-offs. In benchmark tests on up to 1,024 AMD MI300X GPUs, TSP consistently delivers lower per-GPU peak memory than any standard parallelism scheme currently used, for both training and inference workloads.
To understand the significance of TSP, it's essential to first grasp the two parallelism strategies it combines.
Understanding Existing Parallelism Strategies
Tensor Parallelism (TP) – Splitting Weights
Tensor Parallelism splits model weights across GPUs. For example, a weight matrix in an attention or MLP layer is divided so that each GPU in the TP group holds only a fraction. This directly reduces per-GPU memory occupied by parameters, gradients, and optimizer states—the so-called “model state” memory. However, TP requires collective communication operations (typically all-reduce or reduce-scatter/all-gather pairs) every time a layer is computed. This communication is proportional to activation size, so it becomes increasingly expensive as sequence length grows.
Sequence Parallelism (SP) – Splitting Tokens
Sequence Parallelism takes a different approach. Instead of splitting weights, it splits the input token sequence across GPUs. Each GPU processes only a fraction of the tokens, reducing activation memory and the quadratic cost of attention computation. However, SP leaves model weights fully replicated on every GPU, meaning model-state memory remains exactly the same regardless of how many GPUs you add to the SP group.
In standard multi-dimensional parallelism, engineers combine TP and SP by placing them on orthogonal axes of a device mesh. If you want a TP degree of T and an SP degree of Σ, your model replica consumes T × Σ GPUs. This is expensive in two ways. First, it uses more GPUs for the model-parallel group, leaving fewer available for data-parallel replicas. Second, if T × Σ is large enough to span multiple nodes, some collective communication has to travel over slower inter-node interconnects like InfiniBand or Ethernet instead of high-bandwidth intra-node fabric such as AMD Infinity Fabric or NVIDIA NVLink. Data Parallelism (DP), another common baseline, avoids these costs entirely but replicates all model state on every device, making it impractical for large models or long contexts on its own.
The TSP Breakthrough: Folding Parallelism
TSP's core idea is parallelism folding. Instead of placing TP and SP on separate, orthogonal mesh dimensions, Zyphra collapses both onto a single device-mesh axis of size D. Every GPU in the TSP group simultaneously holds 1/D of the model weights and 1/D of the token sequence. Because both are sharded across the same axis, the communication pattern becomes simpler and more efficient. The folding approach eliminates the need for separate all-reduce and all-gather operations between TP and SP groups. Instead, TSP uses a single fused communication step that reduces overhead. This results in up to 2.6× higher throughput compared to matched TP+SP baselines, while also reducing per-GPU peak memory usage.
Benchmark Performance on AMD MI300X
Zyphra tested TSP on clusters of up to 1,024 AMD MI300X GPUs, comparing it against standard TP+SP combinations. Across both training and inference workloads, TSP consistently achieved lower peak memory consumption on each GPU. For large models with long context lengths, the memory savings were particularly pronounced, as TSP's unified sharding reduces the redundancy that plagues multi-dimensional parallelism. The throughput gains of up to 2.6× come from fewer and more efficient collective communications, as well as better utilization of intra-node bandwidth when the TSP group fits within a single node.
Practical Implications for Training and Inference
TSP’s design is hardware-aware: it minimizes cross-node communication and maximizes the use of fast intra-node links. This is especially valuable for folding parallelism into existing clusters without requiring changes to network topology. For AI engineers scaling up transformer models, TSP offers a practical drop-in alternative to manual TP/SP tuning. It simplifies deployment because the parallelism degree D can be chosen to match node size (e.g., 8 GPUs per node), ensuring all communication stays on high-bandwidth fabrics. The lower memory footprint also allows larger models or longer sequences to fit on the same hardware, accelerating both training and inference.
In summary, Zyphra's TSP represents a significant step forward in memory management for large language models. By folding tensor and sequence parallelism into a single efficient axis, it reduces complexity and cuts memory usage while boosting throughput. As models continue to grow, techniques like TSP will become essential for squeezing maximum performance from modern GPU clusters.